1 Internal Workings of MATLAB
1.1 Floating-Point Arithmetic
Since computers have limited resources, only a finite strict subset \(\mathcal{F}\) of the real numbers can be represented. This set of possible stored values is known as Floating-Point Numbers and these are characterised by properties that are different from those in \(\mathbb{R}\), since any real number \(x\) is – in principle – truncated by the computer, giving rise to a new number denoted by \(fl(x)\), which does not necessarily coincide with the original number \(x\).
A computer represents a real number \(x\) as a floating-point number in \(\mathcal{F}\) as \[ x = (-1)^s \times (a_1a_2\dots a_t) \times \beta^E \tag{1.1}\] where:
- \(s\in\{0,1\}\) determines the sign of the number;
- \(\beta\geq 2\) is the base;
- \(E\in\mathbb{Z}\) is the exponent.
- \(a_1a_2\dots a_t\) is the mantissa (or significand). The mantissa has length \(t\) which is the maximum number of digits that can be stored. Each term in the mantissa must satisfy \(0\leq a_i\leq\beta-1\) for all \(i=1,2,\dots,t\) and \(a_1 \neq 0\) (to ensure that the same number cannot have different representations). The digits \(a_1a_2\dots a_p\) (with \(p\leq t\)) are often called the \(p\) first significant digits of \(x\).
The set \(\mathcal{F}\) is therefore fully characterised by the basis \(\beta\), the number of significant digits \(t\) and the range of values that \(E\) can take.
A computer typically uses binary representation, meaning that the base is \(\beta=2\) with the available digits \(\{0,1\}\) (also known as bits) and each digit is the coefficient of a power of 2. Available platforms (like MATLAB and Python) typically use the IEEE754 double precision format for \(\mathcal{F}\), which uses 64-bits as follows:
- 1 bit for \(s\) (either 0 or 1) to determine the sign;
- 11 bits for \(E\) (which can be \(0,1,2,\dots,10\));
- 52 bits for \(a_2 a_3 \dots a_{53}\) (since \(a_1\neq 0\), it has to be equal to 1).
For 32-bit storage, the exponent is at most 7 and the mantissa has 23 digits. Note that 0 does not belong to \(\mathcal{F}\) since it cannot be represented in the form shown in Equation 1.1 and it is therefore handled separately.
The smallest and the largest positive real numbers that can be written in floating points can be found by using the realmin and realmax commands. A positive number smaller than \(x_{\min}\) yields underflow and a positive number greater than \(x_{\max}\) yields overflow. The elements in \(\mathcal{F}\) are more dense near \(x_{\min}\), and less dense while approaching \(x_{\max}\). However, the relative distance is small in both cases. Note that any number bigger than realmax or smaller than -realmax will be assigned the values \(\infty\) and \(-\infty\) respectively.
If a non-zero real number \(x\) is replaced by its floating-point representation \(fl(x)\in\mathcal{F}\), then there will inevitably be a round-off error, especially if the number is either too large or too small relative to the other numbers involved. For a floating point number \(x\), there is a distance \(\varepsilon_x\) where any value in the interval \((x-\varepsilon_x,x+\varepsilon_x)\) cannot be written as a floating point and will therefore be assigned the value \(x\). This interval width is called the Machine Epsilon and can be found for any floating point number \(x\) by using the command eps(x).
The larger the floating number is, the larger the machine epsilon will be, meaning that larger numbers will have much greater tolerances of error. The smaller the number is, the larger the relative size will be, rendering the numbers insginifciant overall.
Since \(\mathcal{F}\) is a strict subset of \(\mathbb{R}\), elementary algebraic operations on floating-point numbers do not inherit all the properties of analogous operations on \(\mathbb{R}\). Precisely, commutativity still holds for addition and multiplication, i.e. \(fl(x + y) = fl(y + x)\) and \(fl(xy) = fl(yx)\). Associativity is violated whenever a situation of overflow or underflow occurs or, similarly, whenever two numbers with opposite signs but similar absolute values are added, the result may be quite inexact and the situation is referred to as loss of significant digits.
Properly handling floating point computations can be tricky sometimes and, if not correctly done, may have serious consequences. There are many webpages (and books) collecting examples of different disasters caused by a poor handling of computer arithmetic or a bad algorithmic implementation. See, for instance, Software Bugs and the Patriot Missile Fail among others.
1.2 Computational Complexity
The Computational Complexity of an algorithm can be defined as the relationship between the size of the input and the difficulty of running the algorithm to completion. The size (or at least, an attribute of the size) of the input is usually denoted \(n\), for instance, for a 1-D array, \(n\) can be its length.
The difficulty of a problem can be measured in several ways. One suitable way to describe the difficulty of the problem is to count the number of Floating-Point Operations, such as additions, subtractions, multiplications, divisions and assignments. Floating-point operations, also called flops, usually measures the speed of a computer, measured as the maximum number of floating-point operations which the computer can execute in one second. Although each basic operation takes a different amount of time, the number of basic operations needed to complete a function is sufficiently related to the running time to be useful, and it is usually easy to count and less dependent on the specific machine (hardware) that is used to perform the computations.
A common notation for complexity is the Big-O notation (denoted \(\mathcal{O}\)), which establishes the relationship in the growth of the number of basic operations with respect to the size of the input as the input size becomes very large. In general, the basic operations grow in direct response to the increase in the size \(n\) of the input and, as \(n\) gets large, the highest power dominates. Therefore, only the highest power term is included in Big-O notation; moreover, coefficients are not required to characterise growth and are usually dropped (although this will also depend on the precision of the estimates).
Formally, a function \(f\) behaves as \(f(x) \sim \mathcal{O}\left(p(x)\right)\) as \(x\) tends to infinity if \[\lim_{x \to \infty}\frac{f(x)}{p(x)}=\text{constant}.\] For example, the polynomial \(f(x)=x^4+2x^2+x+5\) behaves like \(x^4\) as \(x\) tends to infinity since this term will be the fastest to grow. This can be written as \(f(x) \sim \mathcal{O}\left(x^4\right)\) as \(x \to \infty\).
For more complicated codes, it is important to see where most of the time is spent in a code and how execution can be improved. A rudimentary way of timing can be done by the toc toc:
This will produce a simple time in seconds that MATLAB took from tic until toc, so if toc has not been types, then the timer will continue.
For more advanced analysis, MATLAB uses a Code Profiler to analyse code which includes run times for each iteration, times a code has been called and a lot more.
Suppose that a code needs to be written that finds the \({N}^{\mathrm{th}}\) Fibonacci number starting the sequence with (1,1). This can be done in two ways:
- Iteratively by having a self-contained code that generates all the terms of the sequence up to \(N\) and displays the last term.
- Recursively by have a self-referential code that keeps referring back to itself to generate the last term in the sequence from the previous terms.
When running these codes for an input of \(N=10\), the times are very short, of the order of \(10^{-5}\) seconds but as \(N\) gets larger, the recursive code starts to take much longer. Suppose the code efficiency is to be analysed for the input \(N=40\), this can be done using the profiler as follows:
This will give a full breakdown of how many times every line was run and how much time it took. For Fib_Iter(40), a total of 38 operations were performed, each taking such a short amount of time that it registers as “0 seconds”.
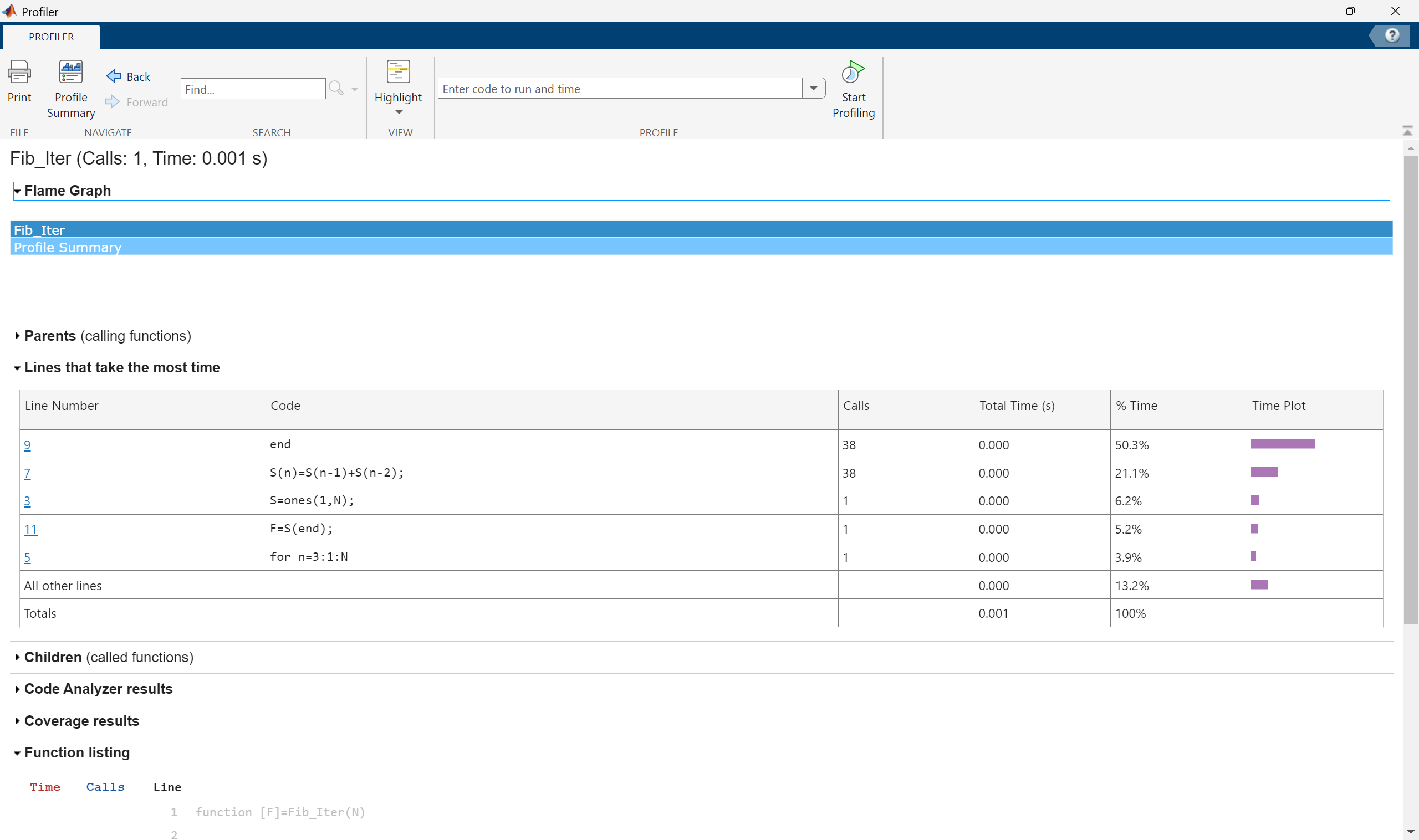
However, performing the profiler for Fib_Rec(40) gives a dramatically different answer with the code taking nearly 247 seconds and having to call itself more than 102 million times.
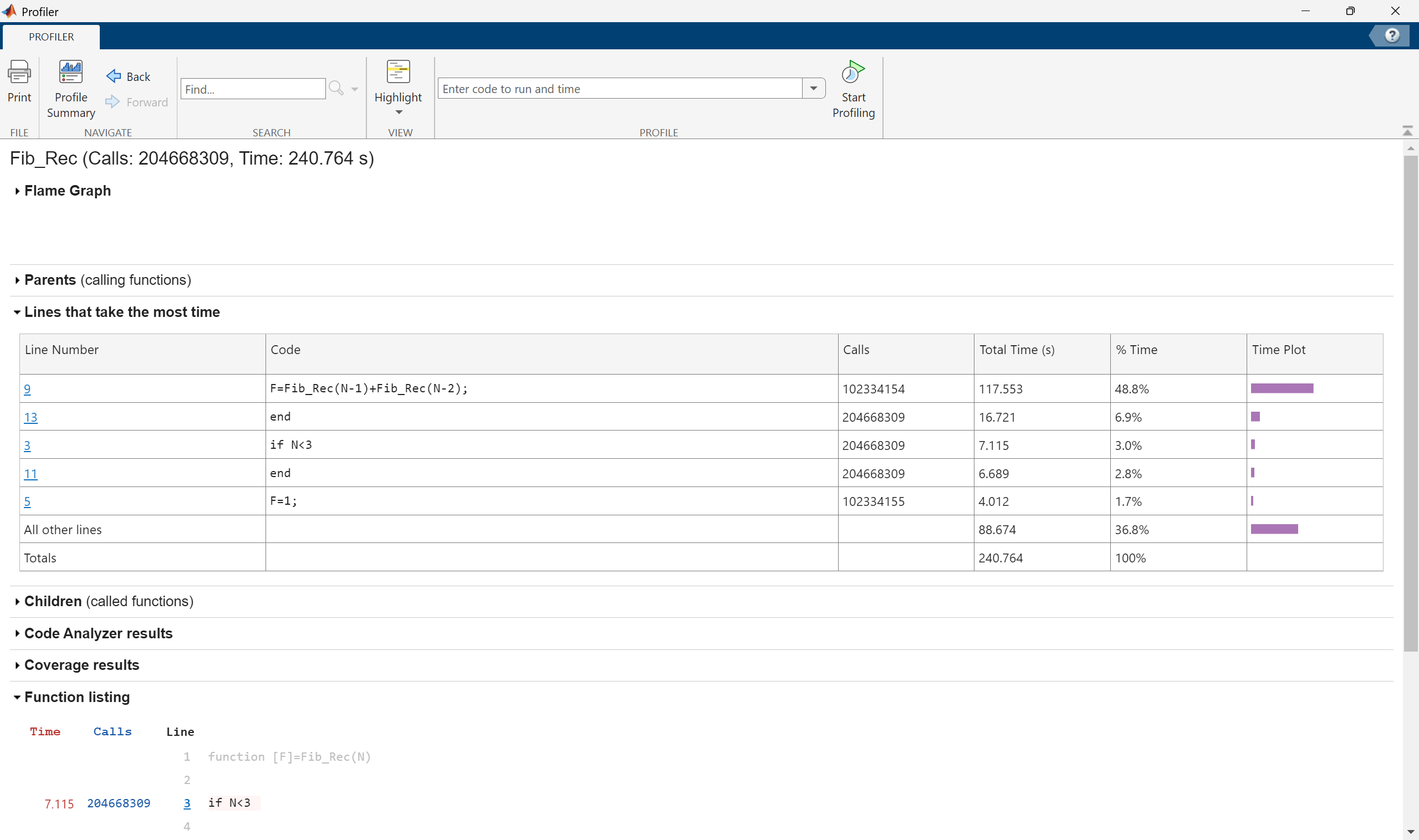
This is why it is important to profile longer codes to see which parts take the longest time and which loops are the most time consuming.
To reduce computational time in general, avoid self-referential codes because these tend to grow in usage exponentially. Another important practice is to use in-built MATLAB syntax, like using sum to add elements in a vector rather than manually hard coding it. This is where being familiar with a lot of the MATLAB syntax is important; MATLAB has a lot of built-in codes and syntaxes which can save a lot of time.